

 / Corpus numériques
/ Corpus numériques
Œuvres complètes de Mussolini
Présentation
Nous présentons ici les résultats d’une analyse textométrique des Œuvres Complètes de Mussolini, réalisée en collaboration avec Stéphanie Lanfranchi et Elise Varcin du laboratoire Triangle, à l’ENS Lyon.
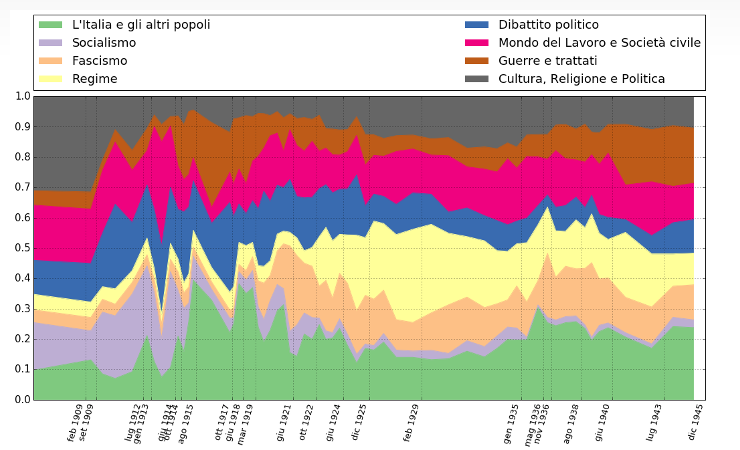
Sources et enjeux de cette étude
Les Œuvres Complètes de Mussolini, éditées par D. et E. Susmel forment un corpus d’un quarantaine de volumes rassemblant des textes publics (articles, discours, romans...) et des communications privées (lettres, télégrammes...). Nous nous sommes concentrés dans cette étude sur les communications publiques, qui réunissent environ 6000 textes.
Le but de cet étude est de construire une vision globale de ce corpus, qui par sa taille échappe à une étude purement philologique. Pour cela nous avons utilisé des techniques de fouilles de données, type text mining, qui relèvent des Big Data. L’idée de base est que la quantité de textes permet d’utiliser la puissance de ces outils.
Le résultat de cette étude est la définition de 120 sous-thèmes qui permettent une vision globale des Œuvres Complètes. Chacun de ces thèmes a une importance, qui varie au cours des quarante années couvertes par le corpus. Pour une plus grande lisibilité, ces thèmes ont été d’abord regroupés en thèmes plus généraux, puis en 8 super-thèmes. La figure ci-dessus donne une vision de l’évolution de l’importance de ces 8 super-thèmes.
Nous décrivons sur ce site le type d’analyse que nous avons réalisée, ce qu’est un thème. Nous exposons les résultats bruts de cette analyse en présentant tous les thèmes et leur évolution chronologique.
Qu’est-ce qu’un thème ?
Nous nous arrêtons ici sur le concept même de thème, et nous essayons d’expliquer comment nous avons interprété les résultats bruts de l’analyse statistique. Cette analyse est décrite plus précisément plus bas.
D’une liste de mots à un thème identifié
Le premier résultat qui sort de l’analyse statistique est une liste de 120 listes de mots, chaque mot ayant une importance, mesurée par un nombre entre 0 et 1. Par exemple, une des listes est la suivante (nous montrons les mots les plus importants) :
patria (patrie) (poids : 0.04), fede (foi) (poids : 0.01), cuore (coeur) (poids : 0.01), sacrificio (sacrifice) (poids : 0.01), gloria (gloire) (poids : 0.01), sangue (sang) (poids : 0.01), giovane (jeune) (poids : 0.01), madre (mère) (poids : 0.01), dovere (devoir) (peso : 0.01), caduto (tombé) (poids : 0.01), grande (grand) (poids : 0.01), morto (mort) (poids : 0.01), figlio (fils) (poids : 0.01), bandiera (drapeau) (poids : 0.01), nome (nom) (poids : 0.01), grandezza (grandeur) (poids : 0.01), amore (amour) (poids : 0.01), glorioso (glorieux) (poids : 0.01)
Rappelons que cette liste de mot a été construite par une méthode statistique qui ne prend en compte que les occurrences des différents mots dans les différents textes. En particulier la sémantique est complètement cachée à cette analyse. Il est donc frappant de voir l’homogénéité sémantique de cette liste de mots.
Cette homogénéité est suffisamment grande pour pouvoir identifier cette liste de mots comme un thème de l’œuvre Complète. La liste précédente est assez facilement identifiable comme un thème relevant du patriotisme, et plus particulièrement du sacrifice patriotique. Nous l’avons donc identifié comme Patria e sacrificio (Patrie et sacrifice).
Une autre information : l’évolution chronologique
Une information cruciale fournie par l’analyse statistique est l’évolution de la prégnance du thème à l’étude dans le corpus. Plus concrètement, cette analyse accompagne la liste de mots précédente du graphique suivant :

Que voit-on dans ce graphique ? Nous voyons l’évolution temporelle (entre 1900 et 1945) de l’importance de la liste de mots ci-dessus dans les Œuvres Complètes. Cette importance est mesurée comme un pourcentage (0.1 représente 10%). Rappelons qu’il y a 120 thèmes, et que donc que l’importance "moyenne" est d’environ 0,8%. Ainsi des pics d’importance à 3 ou 4%, comme on en voit sur ce graphique, sont le signe d’une période où le thème est particulièrement prégnant dans la production de Mussolini.
Ces graphiques sont particulièrement utiles pour comprendre les évolutions et les stabilités à l’œuvre dans les écrits de Mussolini. Mentionnons qu’il sont aussi utiles pour identifier les thèmes en permettant de déceler les périodes où ces thèmes apparaissent, ce qui donne un indice sur leur signification.
Concluons en précisant bien que cette étape d’identification est une démarche des chercheurs. Elle est donc bien sûr discutable. C’est une des raisons pour lesquelles nous avons choisi de présenter exhaustivement l’analyse faite (dans la partie Résultats du site dédié), pour permettre à la discussion sur cette identification d’avoir lieu.
Une vue d’ensemble : organisation des thèmes
Une dernière étape de cette analyse est d’organiser les thèmes en thématiques proches. Nous avons choisi de le faire en deux niveaux.
Nous appelons donc les listes de mots, une fois identifiées, des "sous-thèmes". Ce sont les briques de bases de notre analyse. Nous les avons répartis en 24 "thèmes". A ce niveau, nous conservons une assez bonne précision de l’analyse, tout en permettant une vision plus globale. Pour une vue d’ensemble vraiment lisible, nous avons de nouveau répartis ces 24 "thèmes" en 8 "super-thèmes".
Nous présentons cette répartition, avec les évolutions chronologiques, dans la partie Résultats du site dédié.
En cours de chargement...
Description de l’analyse textométrique du corpus de Mussolini
Nous présentons ici la démarche statistique pour construire notre analyse du corpus des Œuvres complètes de Mussolini.
La modélisation thématique (Topic Modelling)
Notre approche relève de la modélisation thématique (topic modelling). Cette approche d’un corpus de texte tente - à partir des simples occurrences des mots dans les différents textes du corpus - de reconstruire une analyse thématique. Il s’agit pour cela et dans un même mouvement de définir des thèmes (tels que présentés ici) et de décrire pour chaque texte en quelles proportions apparaissent les différents thèmes.
Plusieurs algorithmes existent pour effectuer cette modélisation thématique. Nous avons choisi d’utiliser la NMF (Nonnegative Matrix Factorisation). Les détails de cette approche (utilisant un langage mathématique, niveau Licence) sont sur cette page.
En pratique, un certain nombre d’étapes sont nécessaires à la réalisation de cette analyse. Une présentation concrète, avec notamment les moyens informatiques utilisés, se trouvent sur cette page.
Bientôt seront disponibles sur le site dédié au corpus, les deux visualisations du corpus suivantes :
- Modélisation thématique et NMF
- Réalisation pratique de l’analyse